
Originally posted on: https://medium.com/codex/jojogan-style-transfer-on-faces-using-stylegan-create-jojo-faces-cc0907a9bc6
Paper Explained: JoJoGAN — One-Shot Face Stylization

Introduction

JoJoGAN is a style transfer procedure that let you transfer the style of a face image to another style.
It accepts only one style reference image and quickly produces a style mapper that accepts an input and applies the style to the input.

Although it is called JoJoGAN, it can learn any style but not only JoJo style (i.e. the style of an Anime called JoJo).
JoJoGAN Workflow
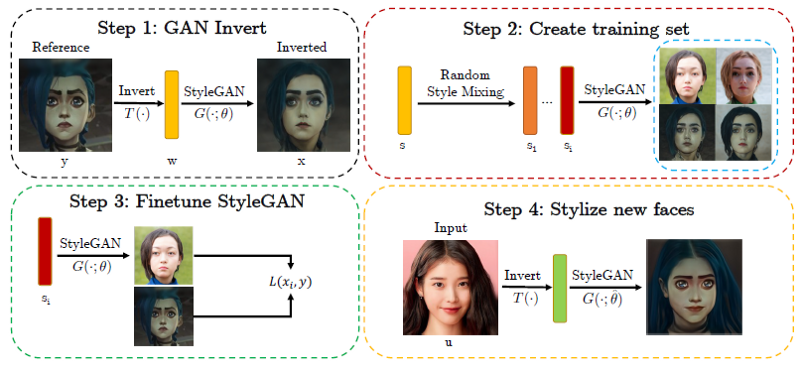
Step 1: GAN inversion
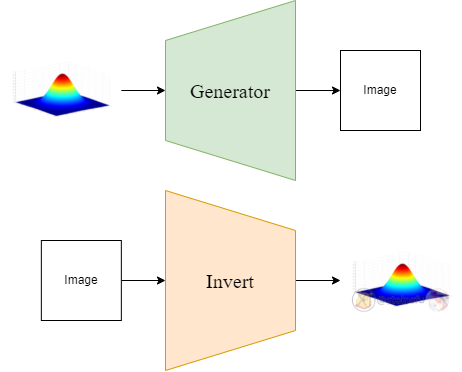
Normally, GAN produces an image from an input latent noise. GAN inversion means obtaining the corresponding latent noise from a given image.
We encode the style reference image y to obtain a latent style code w = T(y) and then from that, we get a set of style parameters s.
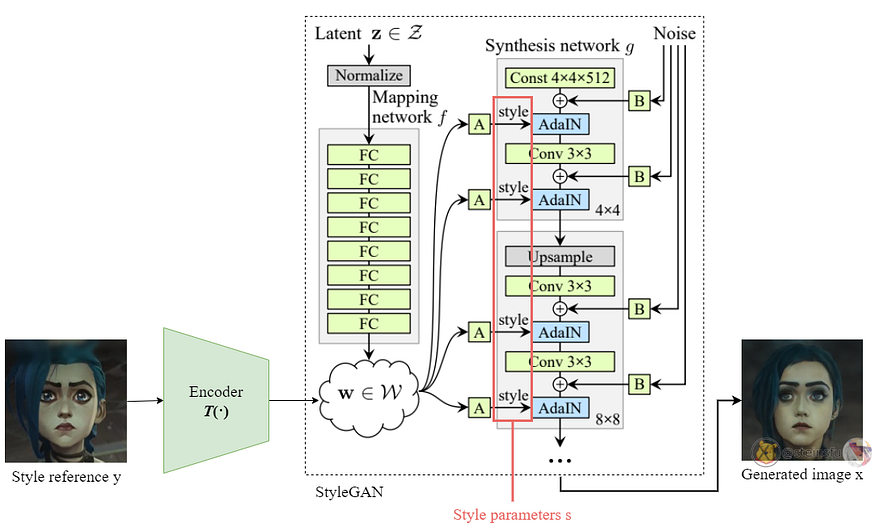
For the choice of GAN inverter (encoder T), the researchers compared e4e, II2S, and ReStyle. They found that ReStyle gives the most accurate reconstruction leading to stylization that better preserves the features and properties of the input.

Step 2: Training set
By using StyleGAN’s style mixing mechanic, we can create a training set to fine-tune the StyleGAN.
Assuming the StyleGAN has 26 style modulation layers, then we define a mask M ∈ {0, 1}²⁶, which is an array of length 26 storing either 0 or 1. By switching M on (1) and off (0) in different layers, we can mix s and s(FC(zᵢ)) to create many pairs (sᵢ, y) for our training set.
We produce new style codes using sᵢ = M · s+(1−M) · s(FC(zᵢ)).
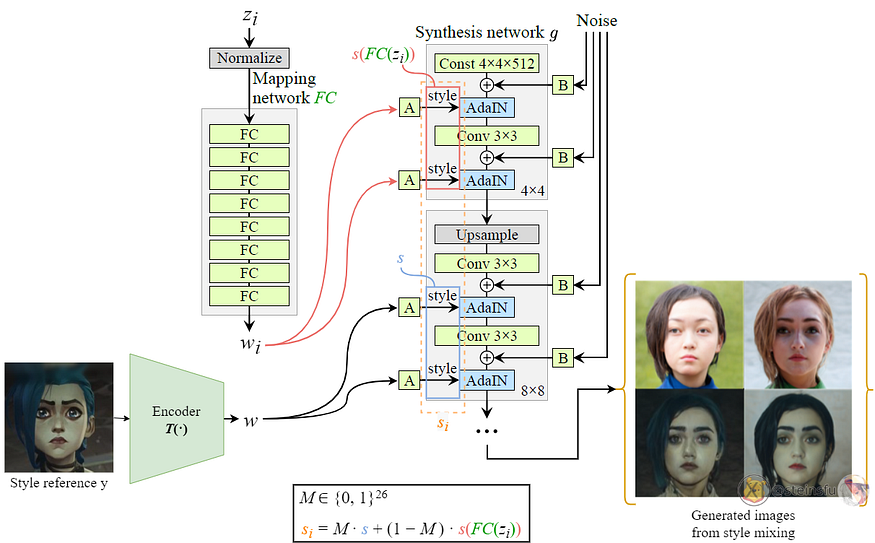
If you don’t know how the StyleGAN’s style mixing mechanic works, it is simply mixing different style codes in different style modulation layers to create different outputs.
For details, you can read the style mixing part of my previous article:
StyleGAN vs StyleGAN2 vs StyleGAN2-ADA vs StyleGAN3
In this article, I will compare and show you the evolution of StyleGAN, StyleGAN2, StyleGAN2-ADA, and StyleGAN3.
Step 3: Finetuning
By using the training set sᵢ, we can fine-tune the StyleGAN to enforce the images generated from these style mixing codes sᵢ to be close to the style reference image y.
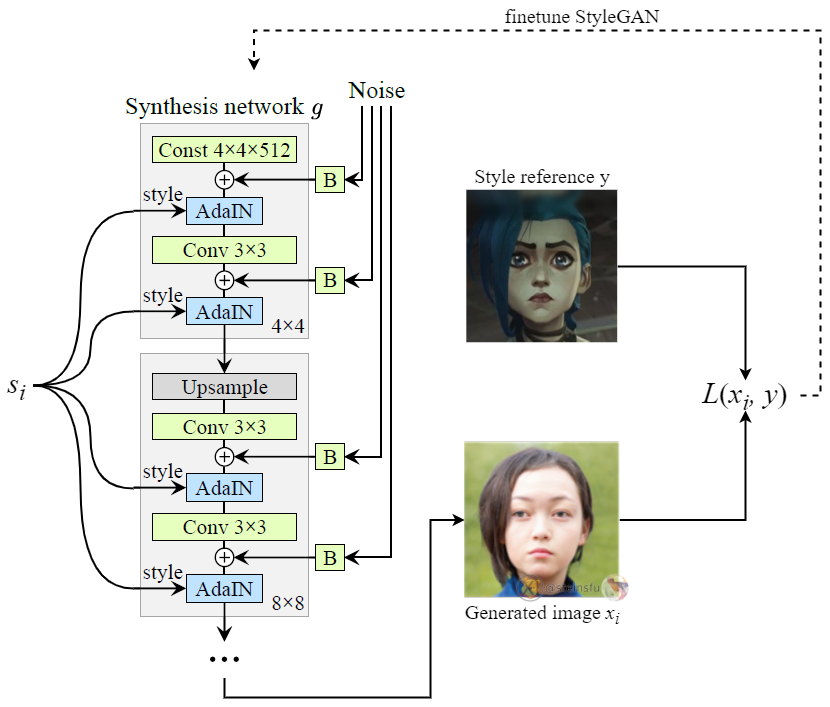
This learns a mapping from an image of any style to the image of a specific style (i.e. style reference y) but preserves the overall spatial contents (i.e. the face/identity of that person).
Step 4: Stylize new faces
After finetuning the StyleGAN, we can simply invert our input to style codes, and then generate an image using the finetuned StyleGAN (which will apply the target style to the generated image).
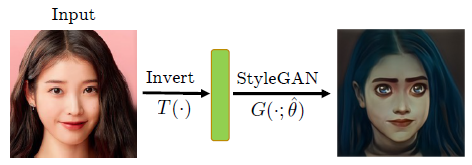
Results


Demo
The authors created a replicate demo and a Colab notebook demo.
Face Not Detected Issue
However, I found that they do not accept complicated style references or inputs. I even tried inputting one of the style images mentioned in the paper, but it just said: “Face not detected”.
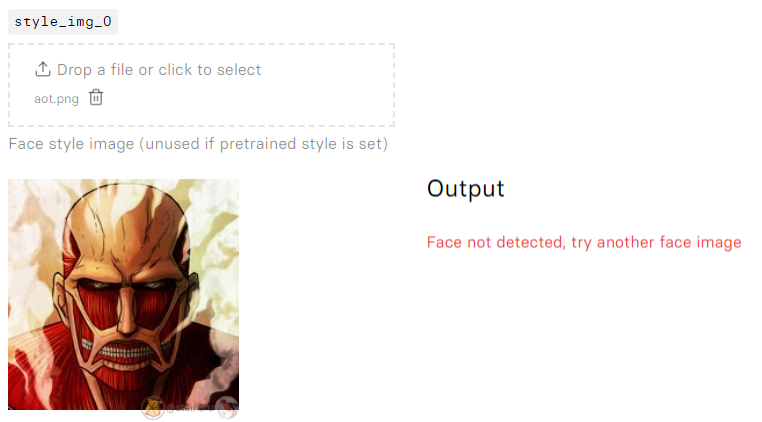
By reviewing their codes, I found out that in the GAN inversion part, they try to do the following:
- Detect and crop the face out of the input image
- Use the cropped image to get the latent code
If face landmarks are not detected in the 1st step, it cannot proceed to the 2nd step.
Fix
I fixed the notebook codes by handling the exception in the 1st step:
- If the 1st step failed, it will continue by using the input image directly
Here is the fixed notebook. You can try it out to stylize more complicated faces.
Google Colaboratory — JoJoGAN_stylize.ipynb
Note: for complicated images, you would like to manually align and crop them into square with face in the center before uploading them to
JoJoGAN/text_input/JoJoGAN/style_images.

Demo Results



Preserve Color


Non-face Style Reference
You can also try out non-face style references, though the results will not be ideal since the inverter and the StyleGAN were pretrained on the FFHQ dataset.


References
[1] M. Chong and D. Forsyth, “JoJoGAN: One-Shot Face Stylization”, arXiv.org, 2022. https://arxiv.org/abs/2112.11641